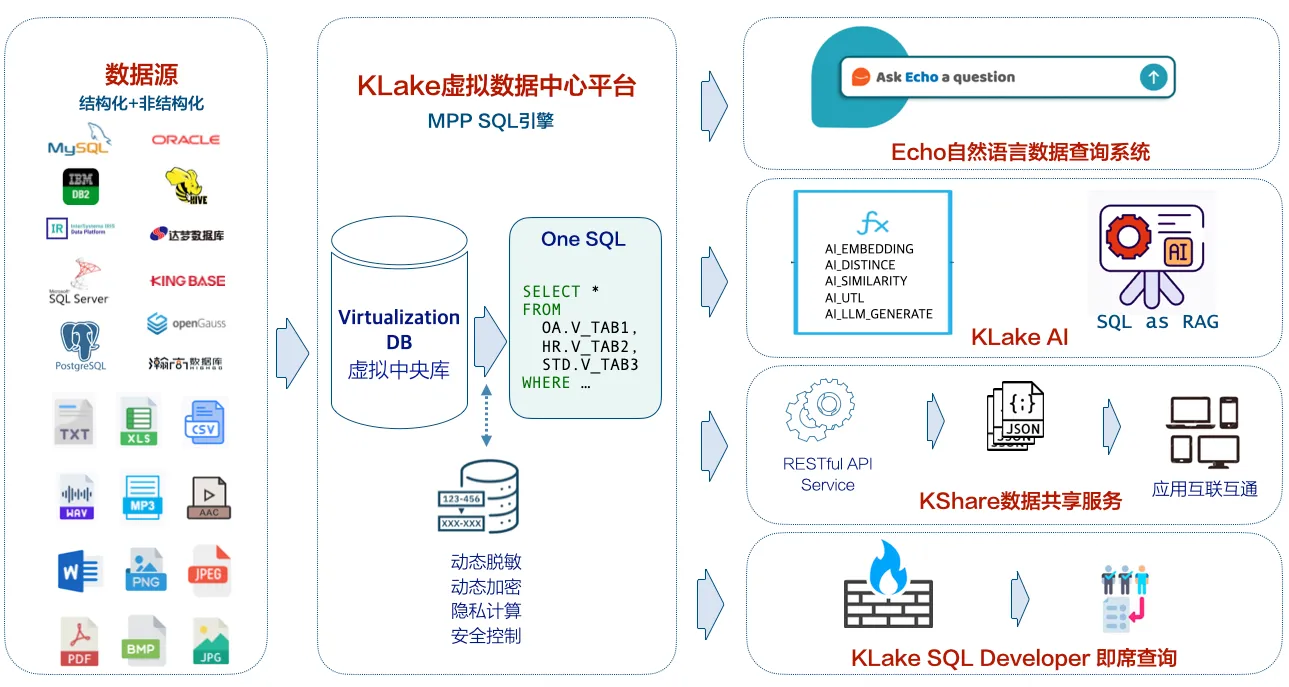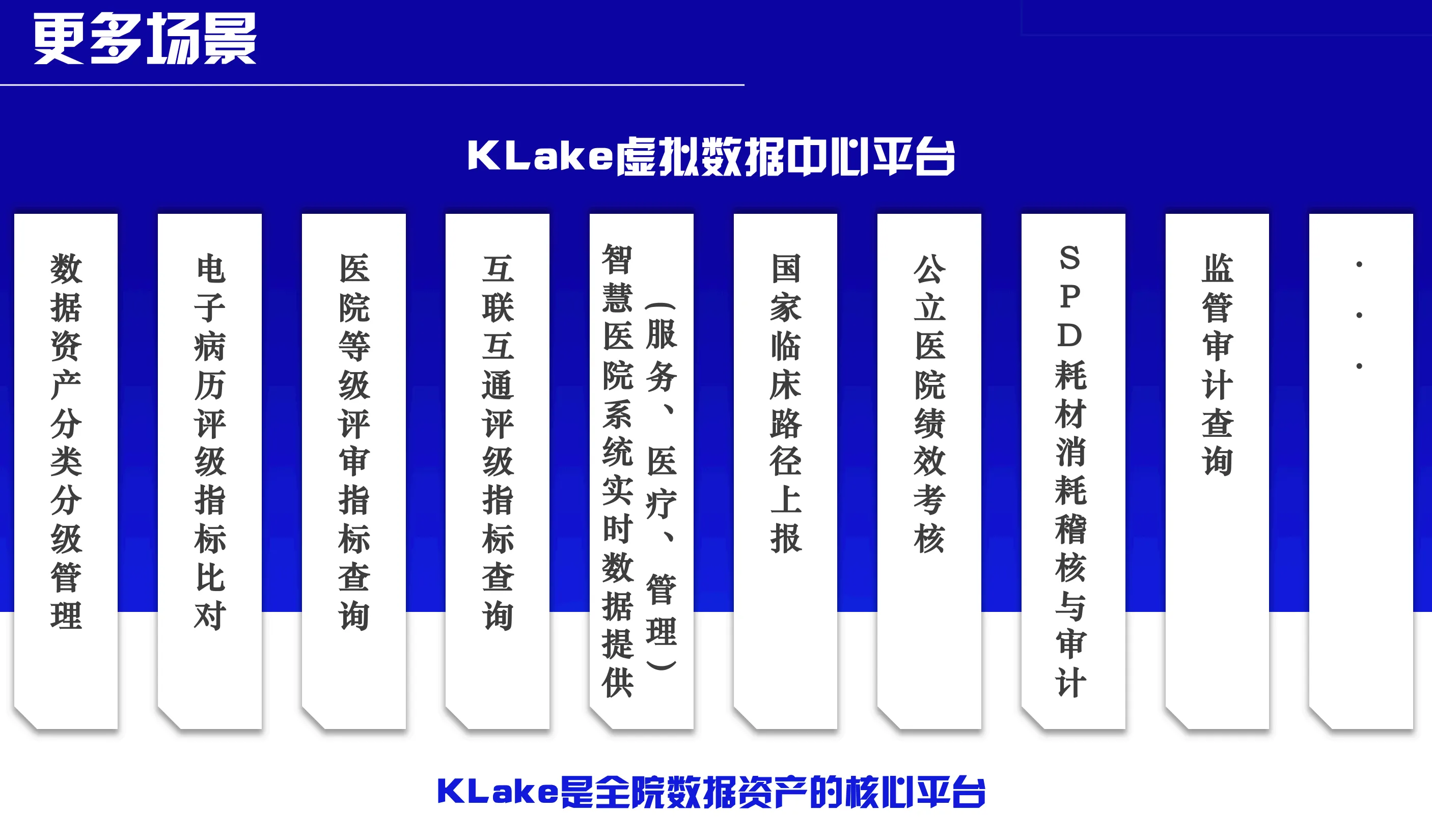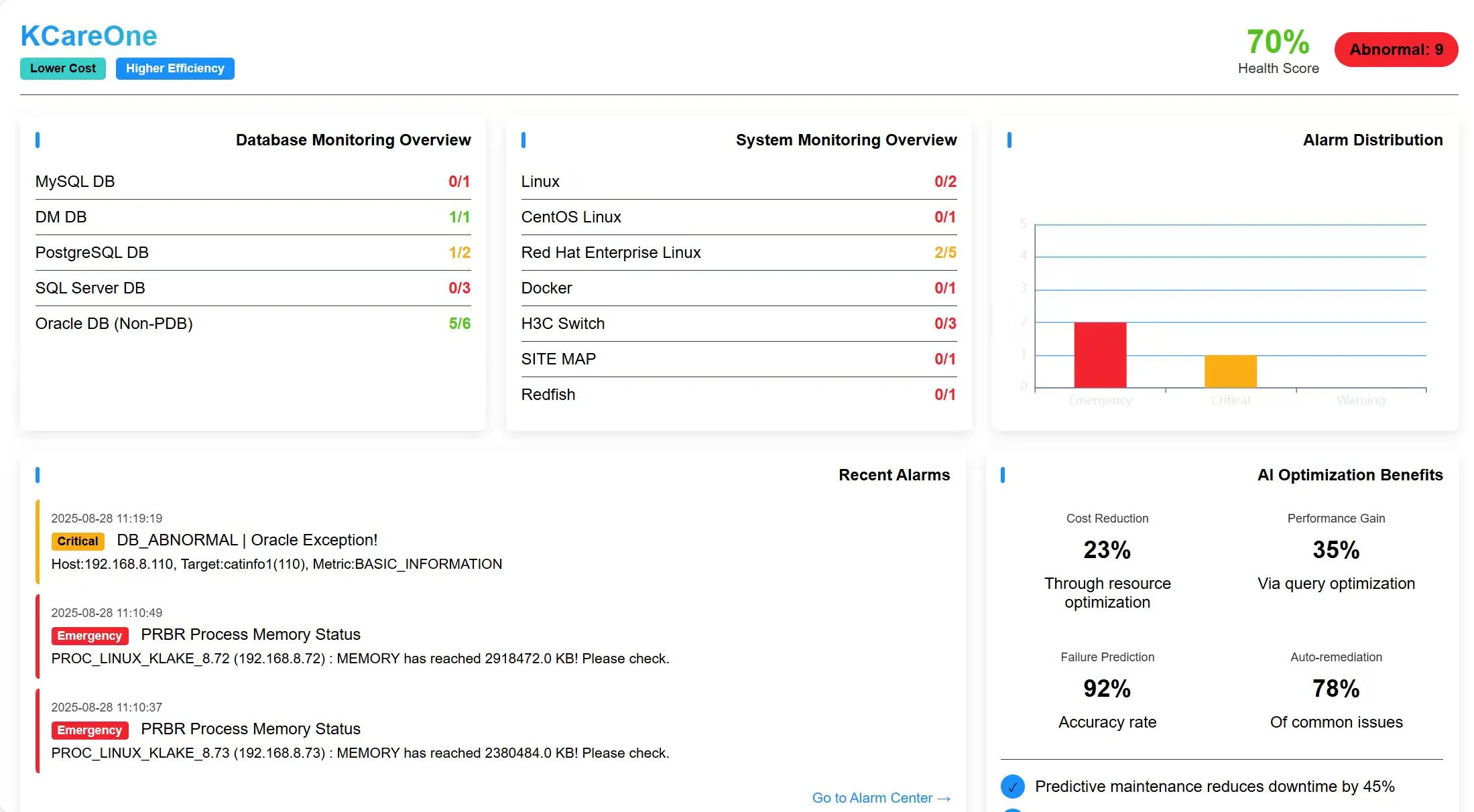

-
①
Данные не в реальном времени
Передаваемые через ETL данные отстают от данных производственных систем и часто требуют повторной обработки из-за несоответствий или проблем с качеством. -
②
Высокие затраты на внедрение
Централизация данных из сотен баз данных с использованием Schema-on-Write требует огромных временных, трудовых и финансовых ресурсов, при этом не позволяя достичь синхронизации в реальном времени. -
③
Узкие места производительности
Как правило, каждой бизнес-базе данных необходимо выполнять задачи по формированию отчетов, синхронизации платформы интеграции и другие. ETL-процессы нагружают исходные базы данных, ухудшая их операционную производительность.
.webp)